
Sounds mysterious, right? Perhaps. As Ebury embraces a more event driven architecture, it’s important we are familiar with key patterns such as CDC and Event Sourcing and when to use them. In this first installment, we’ll go through a CDC example.
What are you talking about?
For the uninitiated, both of these patterns might currently mean nothing to you, so let me step back, what are these ‘patterns’ you speak of?
Both Event Sourcing and Change Data Capture (CDC) are methods for obtaining data from A to B. A might be an external system, such as Salesforce, or Experian, or it could be a legacy internal component that we want to migrate from, such as BOS.
What happened before these patterns?
Without reactive patterns, copying data from one place to another often involved either taking a system offline, or writing changes in (near) real time to a secondary location in a proactive fashion, both had big performance and cost implications.
CDC and event sourcing afford us the opportunity to access (near) real time data in both a cost effective and performant manner.
Now that we’re all experts in what we’re trying to do, why is it important?
The method chosen to obtain the data will have a direct impact on the level of data we are able to obtain. I’ll show you an Ebury example further on.
What’s the goal of these patterns?
Both CDC and Event sourcing are useful for building a single source of truth, providing a reliable history of events in a log that can be used to rebuild state. Both patterns support event driven architecture, allowing other processes to be triggered when an event occurs. Both expose system changes in the form of events, and events represent facts.
What’s the difference then?
The main difference is where the source of truth is taken from, and what that means for the data obtained.
- Event sourcing takes events from the application source, using a journal of domain events
- The state is updated via an append only log, which is generally immutable
- An immutable log provides looser coupling between writes and reads, because it is not based on a specific data model
- Records the action that caused the event – e.g. client cancelled trade
- Change events use the underlying database transaction log as the source of truth
- The event is based on the database that the transaction log belongs to, rather than the original application
- The event is available for as long as the events are persisted (not immutable)
- Based on a mutable database, which means tighter coupling to the database data model
- Records the effect of the event e.g. one trade was deleted from the trade data set
There are use cases for each of these patterns. Ensuring the differences are understood is important to identifying when they should be used.
How about a use case?
Change Data Capture – Salesforce
Today Ebury sources data from Salesforce into BOS, however there is a lot of data within Salesforce that is not currently of interest to BOS, therefore BOS does not consume this. Here are some examples:
- BOS does not consume account data until the account is converted to a client – BOS does not store prospects/leads/opportunities
- Salesforce has circa 500 fields, BOS only consumes a subset of these to meet current requirements
This means BOS does not hold the exact same information as Salesforce, and has modelled the data in a different way to Salesforce (BOS has a data model based around clients and client contacts, Salesforce has a data model based around accounts and account types).
This results in a solution that is built for a specific use case, which can result in inflexibility and inefficiencies when new requirements are provided.
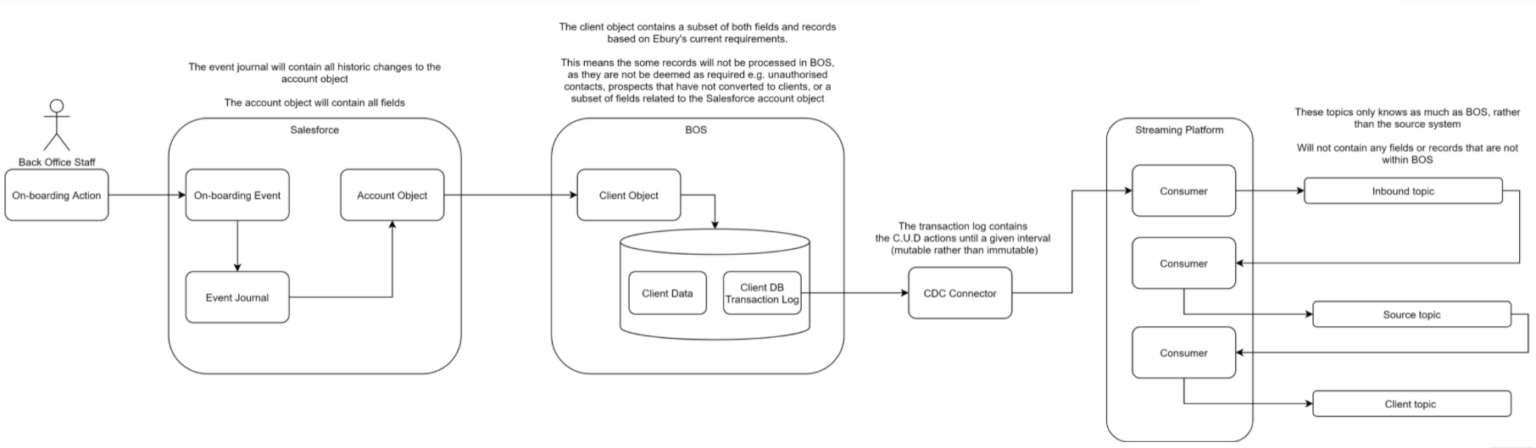
Click to open full size image
Let’s walk through this CDC example:
- An event occurs related to onboarding, which is recorded in Salesforce
- Within Salesforce, there will be a journal of events, capturing each change the onboarding action causes
- These changes are reflected on the account object, which holds the current state of the account
- BOS consumes from the Salesforce account object and takes the data it is interested in. This will be a subset of fields and records, only consuming records relating to an account that has been converted to a client and the fields related to the current requirements
- The client data object is linked to BOS’s client data model, rather than Salesforce’s event journal. The transaction log is based on the BOS client data model.
- The CDC connector reads from the transaction log, and recreates the database transactions (create, update, delete) across onto Kafka topics
- These Kafka topics will only know as much about the data as BOS does, as BOS is the source rather than Salesforce. The information will also be about the effect of the action, rather than the action itself
What’s the impact of this?
- If our requirements change, and we need more of the data in Salesforce that we don’t currently bring into BOS:
- the BOS sourcing logic will need updating
- the client data model will need updating
- the transaction log is mutable, therefore it may not be possible to update previous records with the additional information prior to the data model update
- our single source of the truth doesn’t contain the full raw data from the original source i.e. Salesforce
Look out for part two of this blog – which shall follow shortly with an an event sourcing example and accompanied by a conclusion.