
In the first part of this series, we covered a CDC example, and today we’ll work in an Event Sourcing example.
Event Sourcing – Salesforce
If we used the same integration with event sourcing, consumers would source directly from the application, in this example, Salesforce.
This avoids coupling to BOS’s physical data model, and will allow quicker and easier adjustments to be made to the data available for consumers, without having to update legacy BOS logic.
This creates a solution that isn’t built with any specific use case in mind, therefore is flexible to new requirements, and will allow for custom data models, developed based on their purpose, which adds efficiency.
Click to open full size image
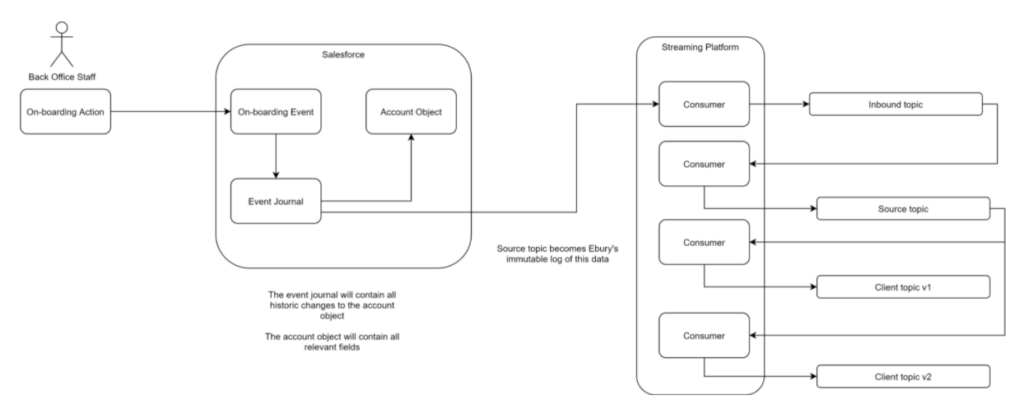
Let’s walk through this Event Sourcing example:
- the same onboarding event occurs in Salesforce as the CDC example
- instead of consuming from the account object, we consume from the event journal (via either Platform Events or one of the other Streaming API services provided by Salesforce)
- this means we are consuming directly from the application’s journal of events, taking the entire data source raw, without filtering out records or fields that aren’t required for today’s requirements
- our inbound consumer conducts high level validation, ensuring data quality controls such as schema validation and any Ebury specific criteria, these raw records are then stored in a ‘source’ topic, which serves as our immutable log of data
- this source data, along with other source data, can then be transformed / joined to create topics for specific use cases, that are then all based on the source of truth. In this example, the client topic will be created based on current requirements, filtering out any fields or records that are not of interest
- if new requirements are provided that require a change in the logic for clients (for example additional fields are needed, or a change in the model is required to bring back prospect records too), because we have sourced the data raw, we create another consumer with different transform logic, and create a v2 of the client topic (or a brand new topic with a different naming convention), without disrupting the sourcing of information flow
- data models are tailored, as long as they are based on data that is in a validated source topic (avoiding duplicate logic)
- CQRS can also be added to source data for reads and writes separately
OK so what does this mean for Ebury – is CDC always right or wrong?
CDC is not often the end goal, and its use should be carefully considered.
CDC has many advantages, allowing real time data transactions to be delivered to new data stores, enabling low latency, efficient data transfer to other users without having a big impact on production.
It allows for data replication to make data available for different purposes, such as search indexes or analytics.
It’s useful within the same bounded context in relation to its own physical data model (generic example below from DZone).
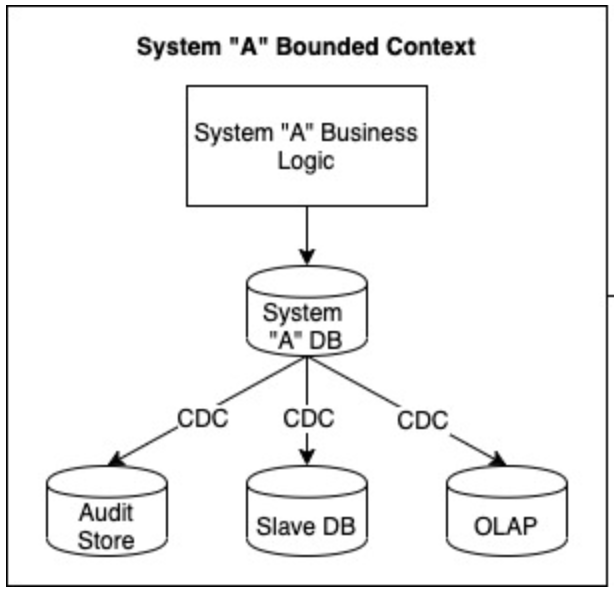
CDC is also useful when the original source of the data is unobtainable, therefore the database is the closest source available.
However, its limitations mean that it usually involves building for a specific use case in mind, and that can be detrimental when trying to accommodate future requirements.
How does my choice of sourcing impact data?
Whether CDC or event sourcing, the aim is to get a single source of the truth, as this is one of the key data principles.
However, the method we choose for sourcing can have an impact on the data and other key data principles. We require the ability to retain ‘raw’ data where possible and stored in the original state before we process it further. Again, this allows us to replay the data if our processing rules change in future.
Sourcing via CDC does not give the raw data state, and is always subject to some form of processing by the database that the transaction log is taken from.
Hopefully this gives an insight into the differences and use cases for event sourcing and CDC.