When designing any new service to be included within Ebury‘s event driven architecture, we need to define the way producers and consumers will behave. This includes describing the structure of the events being produced, in order to enable downstream consumers to read them.
Kafka is used to communicate between services. As such, Kafka only moves bytes across the infrastructure, not caring about the content of those bytes. As no parsing nor reading is done from Kafka at all, any malformation or mismatch between producers and consumers can have a great impact in our business, thus architectural design must be as resilient as possible.
In order to achieve that, we are defining company wide schemas to structure data, making both producers and consumers synced with previously agreed on models.
To make the most out of the tradeoffs between good readability and data processing capacities, we have chosen Apache Avro.
Apache Avro
![]()
In short, Avro is a data serialisation format, which allows us to define the data schema in JSON, and serialises the data in a compact binary format. Data modelling can be defined in a structured way, and later be stored in .avsc (avro schema) files.
The following Avro schema describes the basic shape of a Client:
{
"type": "record",
"namespace": "ebury.schemas",
"name": "ClientSchema",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": null}
]
}
To model the set of fields within a schema, Avro supports the following primitive types:
- null: No value
- boolean: Binary value
- int: 32-bit signed integer
- long: 64-bit signed integer
- float: 32-bit single precision floating point number (IEEE 754)
- double: 64-bit double precision floating point number (IEEE 754)
- bytes: 8-bit unsigned bytes sequence
- string: Unicode character sequence
Moreover, Avro also supports complex data types, such as:
- Record: Represents a collection of multiple attributes (as seen in the Client schema itself)
- Enum: List of predefined items in a collection
- Array: List of single attribute items
- Map: Array of key-value pairs
- Union: Allowing for more than 1 datatype (email field in the Client schema)
- Fixed: Fixed-sized field (in bytes)
The combination and nesting of these types can create elaborated definitions to suit our needs. Each section of an Avro definition can also be enriched thanks to the built-in doc field, so that any human readers can interpret the meaning of its content.
Avro data instances can later be encoded in binary format to be exchanged between services. When Avro data is stored in a file, both values and structure are stored within, so that any process can have access to the whole self-contained package.
Data changes
Nevertheless, no matter how much effort we put on data modelling, we are not able to foresee all the changes it might experience: new business opportunities, internal services expansion, need to adapt to new scenarios… Schemas will evolve over time, and it must be taken care of.
Every time a new version for a schema is to be developed, 4 different scenarios can arise:
Backward compatibility
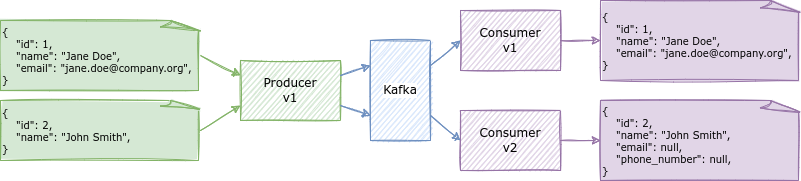
When consumers updated to a new version of the schema can read data produced with an older version, we talk about Backward compatibility.
For example, given we update the previous ClientSchema as:
{
"type": "record",
"namespace": "ebury.schemas",
"name": "ClientSchema",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "email", "type": ["null", "string"], "default": null},
{"name": "phone_number", "type": ["null", "int"], "default": null},
]
}
Instances produced with a previous version of the schema can be read by updated consumers. In the following figure, it can be observed how those properties which were not present in the old version are filled with the default values present in the latest one.
Forward compatibility
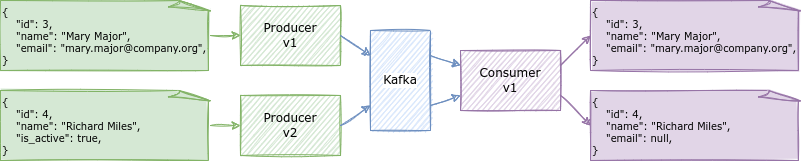
Takes place when consumers configured to read data with an older version are capable of processing instances produced with a newer version.
If producers are updated to create events with the following schema:
{
"type": "record",
"namespace": "ebury.schemas",
"name": "ClientSchema",
"fields": [
{"name": "id", "type": "int"},
{"name": "name", "type": "string"},
{"name": "is_active", "type": "boolean", "default": true},
]
}
Consumers using the original version of ClientSchema will be able to process new definitions, setting default values as placeholders for any no-longer existing field. However, added fields old schemas are not aware of (e.g., is_active) will not be available for its consumption, preventing from making it usable in further processing.
Full compatibility
Every change creating a version both backward and forward compatible, is known to be a full compatibility update.
The addition and removal of fields with a default value is considered a fully compatible change, as services could rely on the default values if fields are missing.
No compatibility
On the other hand, when a change is not compatible with the previous version, it is considered to be a breaking change. Non-compatible updates will create issues in our services at runtime, as they won’t be able to communicate with each other.
Schema evolution recommendations
To evolve our schemas in the safest way, we should aim to ensure full compatibility whenever possible, as it allows our services to run as they did before any update.
Should only backward or forward compatibility be established, we need to understand the tradeoffs of updating our services, as some values might not be accessible anymore.
Nevertheless, there are some general guidelines to take into account when evolving schemas:
- Primary keys in models should always be required (no default values)
- If any field is expected to be changed in the future, provide a default value
- Be careful with fields with an Enum type, as it can not be changed in future versions
- Do not rename fields, use aliases instead
- Try to always provide default values for new fields
- Do not remove any required field
- Do not change a field’s type
- When introducing a backward compatible change, first update consumers to the latest version, then proceed with producers
- When introducing a forward compatible change, first update producers to the latest version, then proceed with consumers
Wrapping up
Avro allows us to type all our data in a readable and compact fashion, making the most of it through the different services. Its simplicity and integration with other tools and packages makes the data self-explanatory, as both values and their formal definition is available to consumption at any point.
As data requirements change, schemas need to evolve to support new scenarios, and it can be achieved by understanding and taking care of each new structure definition.
Interested in how to manage different schema versions in the most efficient way? Stay tuned to our next article on Schema Registry.