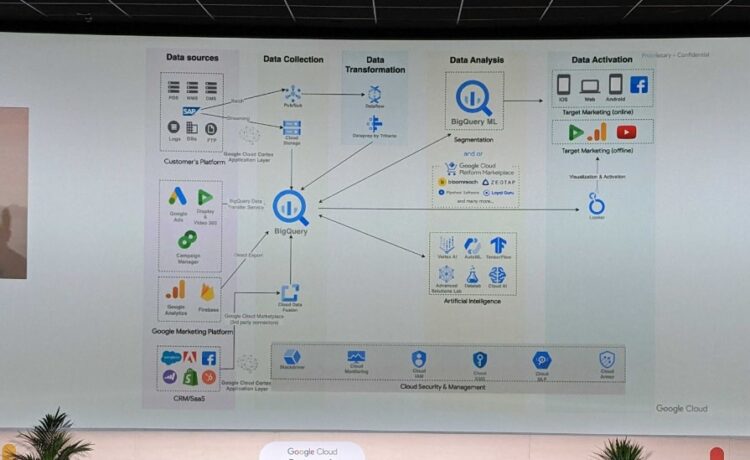
On the 1st of June, some members of the Data Team attended the Google Summit in Madrid, which aimed to acquaint us with the latest trends and advancements in Google Cloud. Our objectives were to gain more knowledge about Google Cloud, establish new connections, and most importantly, bring back valuable insights to Ebury.
Google’s Ideal Data Platform
In the above picture, the ideal, albeit somewhat generic, Data Platform solution was showcased at the event. Google Cloud currently offers a wide range of solutions for various use case scenarios, including data ingestion, transformation, machine learning, and more.
Key Characteristics
BigQuery
As depicted in the image, the focal point was BigQuery. Attending multiple presentations made it evident that BigQuery is undeniably the centrepiece of Google Cloud. It features integrations with numerous tools and is recognized as a leading player in the market.
Real-Time Data
Another significant aspect highlighted at the summit was the increasing importance of real-time data. Reacting promptly to data has become crucial for businesses, and the ability to deliver data and metrics in real-time can often be a complete game-changer.
One of the tools recommended for real-time data management was PubSub, a cloud-based messaging service similar to Kafka.
Data Activation
Lastly, the discussions emphasised that a data platform is no longer just limited to analytical or reporting purposes. With advancements in processing power, artificial intelligence, and the ease of managing data services in the cloud, the impact of a data platform within a company has significantly expanded. Nowadays, the data platform is expected to be a continuous flow through which data is processed, enriched, analysed, and utilised to provide additional value. It forms a complete data full circle, facilitating improvements in products, services, customer experiences, etc.
Ebury’s Current Data Platform
{kind=link}
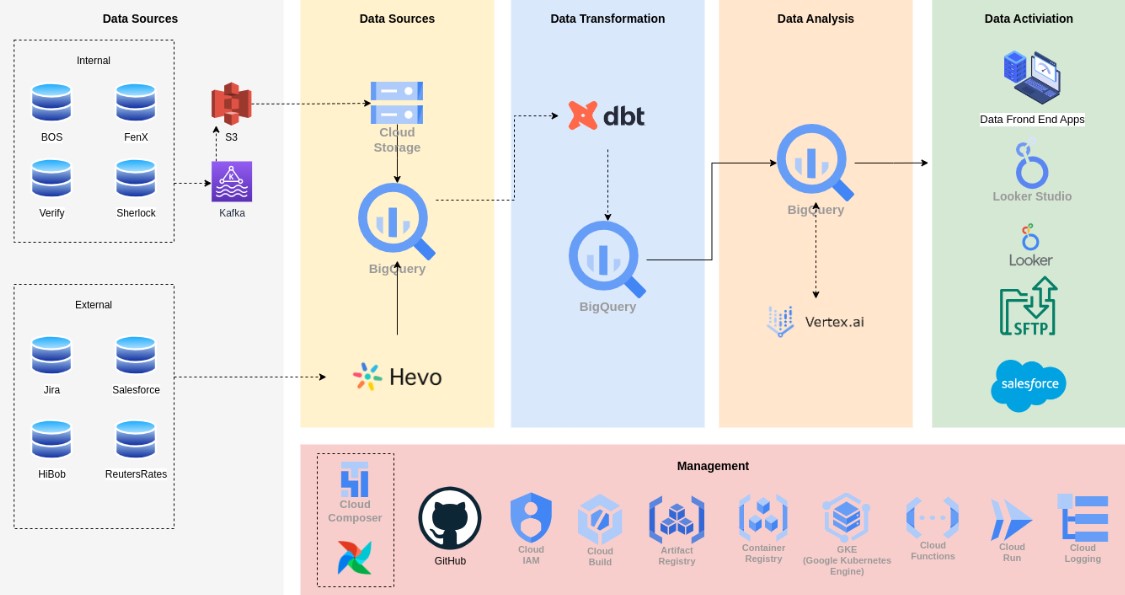
To compare Google’s ideal solution with Ebury’s Data Platform, the diagram above provides a high-level overview of our current platform.
Main differences
The most significant difference between the two diagrams lies in our data processing approach. While Google promotes tools like DataProc or DataFlow, we mainly rely on DBT. Therefore, all our processing is conducted using SQL code, leveraging the processing capabilities of BigQuery.
While this approach is suitable for most cases, Google suggests that companies should consider solutions like DataProc, where processing is done with Spark. This approach offers advantages such as freeing up BigQuery’s resources for analytical tasks and other use cases where BigQuery excels.
In terms of data ingestion, we generally have two methods:
- Kafka/S3: We receive data in batches from S3 to Cloud Storage, and then to BigQuery.
- External service (Hevo): This service allows us to connect to external tools like Salesforce and import the data into our platform.
Possible Next Steps
Upon examining our current diagram and comparing it to Google’s solution, several potential improvements can be considered to enhance our platform.
Real Time Data
One potential upgrade would be to integrate our data ingestion directly into Kafka. By doing so, we could reduce the number of intermediate steps that the data passes through, minimising the risk of errors and enhancing data delivery speed, even in real time.
Data Activation
Another area where we can enhance our platform is data activation. Currently, our data is primarily utilised for analytical and reporting purposes. However, there are significant possibilities for improvement, whether through the implementation of AI or simply by enriching the data we feed back into our systems.