Using a data-driven approach to handle most of the business requirements has become a must-have for modern companies. The amount of data generated by several applications is huge and such data can be useful for decision-making processes and new product creation.
In order to manage the number of different processes a company needs to use different software. This comes with a big challenge: managing the data generated for each application.
The way each of these software stores data can be different. We have a lot of database types out there and each system works with the one that best fits its requirements.
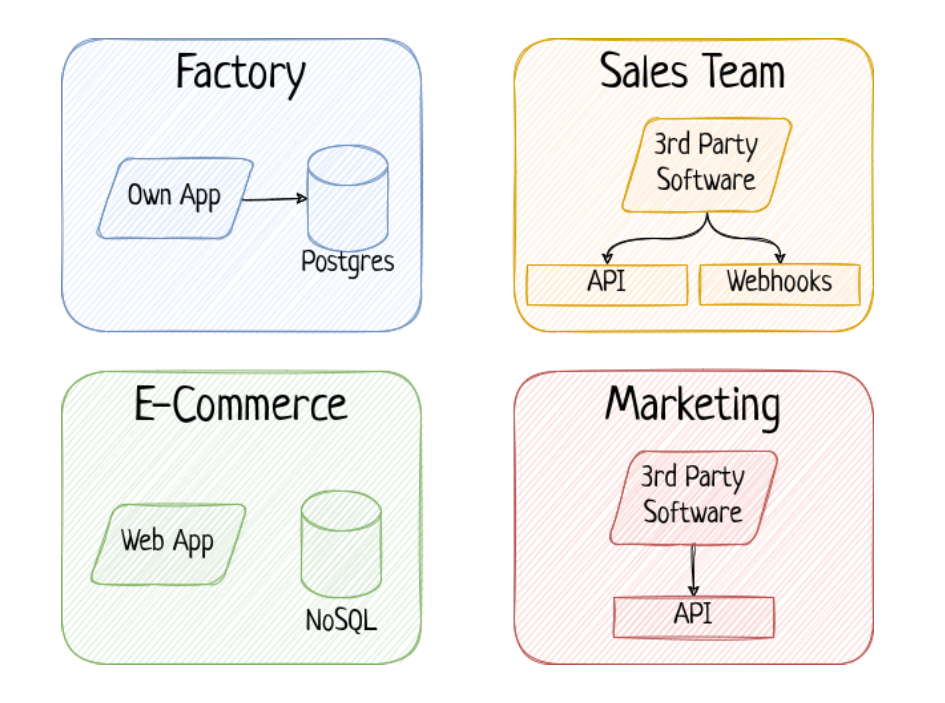
The below image shows a fictitious company with a possible and very common scenario:
How to manage the data?
You can imagine yourself trying to combine data coming from different softwares to make a decision. First question would be: how do I get the required data?
Consider the image shown above. There are two applications providing data through API and two other applications saving data to different databases: one relational database and another nonsql database.
Whoever wants to combine data from those applications will face following challenges:
- Extract data from each application using different approaches for each of them;
- Understand the schema and meaning of each column;
- Take care to not overload the applications;
- Find a solution to combine different file formats (csv, json, xlsx, etc).
It’s hard to imagine a company with a lot of people extracting data by themselves and taking care of all the listed challenges.
One solution would be to extract data periodically from those applications and save the data somewhere else to be later accessed. We can apply some data transformations and make it easier for those who need to consume the data.
Data Platform
Considering the various data management challenges that have been mentioned earlier, and the numerous technical challenges not covered in this article, it is safe to say that a data platform is crucial for handling the large volume of data generated by diverse sources.
At Ebury, we rely on a Data Platform running on the Google Cloud Platform. Our Data Platform enables different areas of the company to access the required in a proper way, accelerating the data-driven processes.
The Data Platform has features to achieve the most known keyword in data project: ETL (extract, transform, and load). We have the ability to extract data from sheets, relational and non-relational databases, API endpoints, webhooks, and many more sources.
With the correct tools, we are able to transform the data, apply data quality checks and load it in an appropriate way to enable the stakeholders to consume it using SQL, a standard language for Data Analytics workloads.
How do we do that?
In order to achieve this goal of providing an easy-to-use interface for accessing the data, we have data pipelines. Data pipelines are a combination of a series of processes to extract the data from the sources in a secure way (considering a lot of technical challenges), transform the data, and deliver it.
For data storage, there are two main important pieces of the data platform: data lake and data warehouse.
Below you can find a simple comparison between the two in order to help you to understand both:
| Data Lake | Data Warehouse |
| Very good for saving a huge amount of data in several different formats. It can be used for ML training, data analytics and decision support. | Data Warehouse or Data Mart serving layer can be added to support SQL consumption of data |
| ELT approach | ETL approach |
| Schema on Read | Schema on Write |
| DL paradigm, data is loaded and then transformed at read-time, for instance ‘schema on demand’, with emphasis on data storage in raw un-modelled form | SQL-centric approach |
Our pipelines use the best of the two approaches in order to fill all the different requirements from multiple teams of our company.
At the end of the data pipelines, we have a data warehouse running on BigQuery, a database application from Google Cloud Platform.
Data Management
One of the challenges that a data platform has to handle is data management. It means we also have to care about access control, data profiling, data cataloguing and lineage.
It’s not all the data that can be accessed by anyone in the company so this is also part of the data platform responsibilities.
Summary
Data challenges are present everywhere and having the proper tools setup in order to support the company to manage such challenges is a must-have. The Data Platforms aims to meet these requirements and make the data usage easier across the company.
With the data platform:
- The teams can use SQL or any other language to run analytical workloads
- Data Analytics team can provide Dashboards using visualisation tools over the Data Warehouse
- Machine Learning models can be created using the Data
- Decision-making processes can be easily created
- New products can be created by analyzing the data
- And much more!