
At Ebury, we use Django and have followed an ongoing upgrade path from 1.3 to 1.5 to 1.7. During that time we have had an issue that was messing with us. You might be familiar with it.
We use celery for executing asynchronous tasks and Django is our framework with PostgreSQL database.
The issue occurs when an asynchronous task makes use of an object that has been just updated, or created. There is a dependency with the database, the object might not have the updated status when the asynchronous task starts, or not even exists yet.
We are now able to utilise the library django-transaction-hooks, which works with Django 1.6 through 1.8, and has been merged into Django 1.9+.
What is important with this library is that adds the event “on_commit” to manage timing with database transactions. So, we can use this for scheduling when to queue tasks for celery workers. The main advantage comes when we want to queue using an object created into an atomic transaction. Consider the following example:
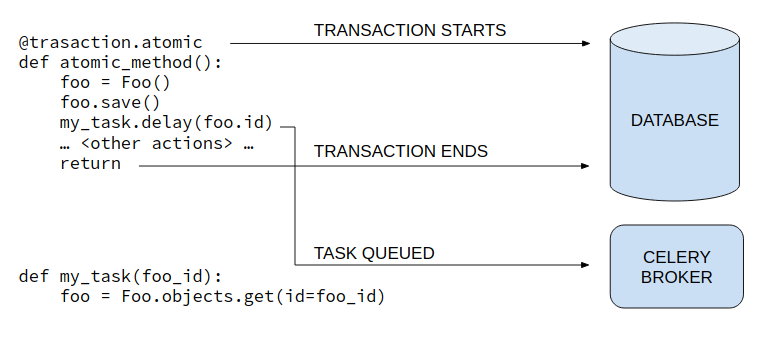
When a task is queued, for instance is not committed into database, and the odds of workers starting tasks with the response “ObjectDoesNotExist” increases with the number of instructions in <other actions>.

With django-transaction-hooks the task is not queued until atomic block is committed.
Essentially, django-transaction-hooks just extends the back-end of the connection with database, managing in memory instructions added with “on_commit” method inside each block, and popping the list out once the transaction ends.
All perfect so far, this suits perfectly with what we want. However, there are two things that still need addressing: compatibility with standard database back-end and an ugly syntax.
As reflected in the library’s documentation, for using it we just need to change settings for the database engine.
DATABASES = {
'default': {
'ENGINE': 'transaction_hooks.backends.postgresql_psycopg2',
'NAME': 'foo',
},
}
However, people through our teams run their environments with a different settings files, depending on their needs, where they could be using a different backend. Calling “connection.on_commit” with django standard back-end will throw an “AttributeError”. So people would be forced to update its database back-end.
Here come across the second point, we don’t like that syntax. I personally hate the lambda syntax, so always try to avoid it. 😉
At the moment we are only using “on_commit” events for queuing to celery, and we have developed our tasks based on Task classes. So, this is the solution we have come up with: set a new method that looks like celery native and wrap compatibility between both engines.
class BaseTask(Task):
"""
Base celery task for trades app
"""
abstract = True
def apply_on_commit(self, args=None, kwargs=None, task_id=None, producer=None,
link=None, link_error=None, **options):
if settings.TRANSACTION_HOOKS_POSTGRE_BACKEND == settings.DATABASES['default']['ENGINE']:
connection.on_commit(lambda: self.apply_async(args, kwargs, task_id, producer,
link, link_error, **options))
else:
self.apply_async(args, kwargs, task_id, producer, link, link_error, **options)
We look for the engine value to call “apply_async” method directly or we can use it with connection “on_commit”. Of course, this would need to be reviewed if we’d use more than one database. But it fits really clean in the code.
This means that as the teams move to utilising this new approach we can maintain compatibility with legacy methods too for a nice controlled adoption.