
This article briefly describes one of the most convenient and powerful ways to generate complex datasets in Salesforce and other systems. I hope it will be interesting for you even if you’re not working with Salesforce. The practice steps below can be applied to a majority of modern relational databases and different file formats.
Why do we need fake data?
Let’s say you’re a Software Engineer, a Quality Assurance Engineer, a Product Owner or any other specialist who is involved in the Software Development Life Cycle (SFDC). It’s obvious that from time to time you need to test your application with a realistic and diverse dataset. It might be needed in the following scenarios:
-
- The Developer builds a prototype of an application.
- QA Engineer analyses the stability of the application.
- Performance Testing Engineer tries to understand how the application works with large data volumes.
- The product Owner prepares a demo for business stakeholders.
- The Data Engineer wants to test their new ML model.
- And so on! There are plenty of possible use cases when you might need realistic data.
Data that meets these scenarios may be difficult to collect, expensive, or protected by different regulations. That’s why finding suitable testing data can become a crucial part of one’s everyday job.
For example, a Salesforce Developer may need a realistic dataset to test their application for Sales Cloud (it’s one of the core Salesforce products). The application includes:
- Lightning Web Components. These are Salesforce Javascript components similar to React components.
- Apex Backend Controllers. Apex is a server-side Salesforce language.
- Apex Batch Jobs. These are long-running asynchronous jobs that can process large volumes of data.
The Developer wants to be sure that the application works well in different scenarios, with different datasets and different volumes. This is especially important for a cloud-native Salesforce platform that shares available resources across thousands of concurrent multi-tenant customers running thousands of applications. Any application exceeding the allocated CPU Time Limit, Heap Size, Available Number of DML Statements or any other hard limit will be immediately “killed” by the platform.
The Developer wants to test the application on a standard Sales Cloud schema (see picture below).
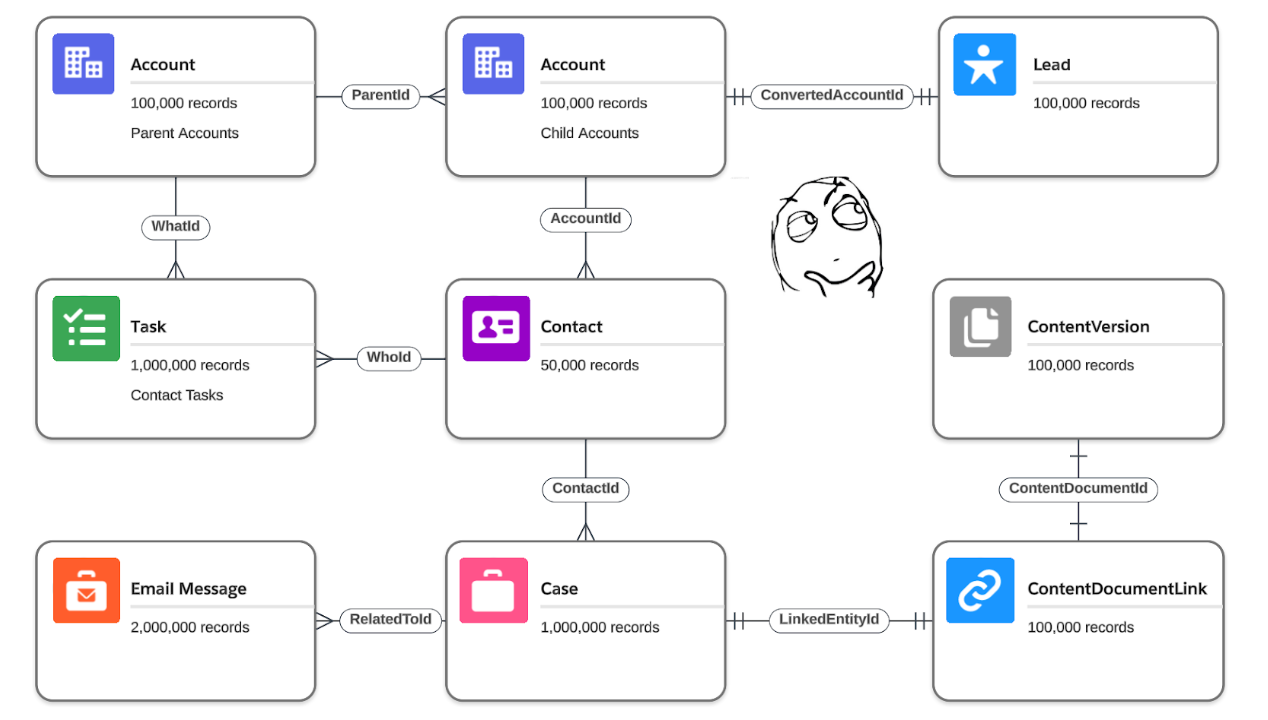
Even if you’re not a Salesforce Developer and you’re not familiar with Sales Cloud, you can see that this schema is pretty complex as it has multiple objects, different types and cardinalities of relationships and high numbers of records for each object. Moreover, ContentVersion and ContentDocumentLink objects in the right bottom corner represent Files in Salesforce (for example, random PDF files). We have the following options to create such data in a sandbox environment:
- Copy Production data to Sandbox. Of course, this is not the best way to feed your sandbox with data unless you want to face regulatory consequences!
- Create all records manually. That’s not our way to do this. Laziness is the mother of invention! And this is just not possible if you want to generate tens of millions of records.
- Copy and (pseudo)anonymise Production data. This is possible only in certain situations. It should be allowed by a compliance team and you should be 1000% sure that you didn’t forget to obfuscate all sensitive data. Additionally, fake data generation tools described in this article can do obfuscation as well.
- Generate synthetic dummy data. By “dummy data” I mean something like “TestAccount1234” or “John_AAA”. Such data is not realistic, but it is good enough to do some testing. This can work for simple tests, but not for something more sophisticated.
- Generate realistic data. This is the right way to do things! Such data will be useful during all phases of the SDLC process and even during the preparation of demos, release notes and marketing materials.
CumulusCI and Snowfakery
This is where CumulusCI and Snowfakery come to the rescue. Both are open-source frameworks maintained by the Salesforce community.
- CumulusCI helps automate Salesforce Org (instance) setup, testing and deployment. It has tons of various features, such as applying transformations on Salesforce metadata, creating end-to-end browser tests, running builds in continuous integration systems, etc. All the features are available through the Command-Line Interface similar to SFDX CLI or AWS CLI.
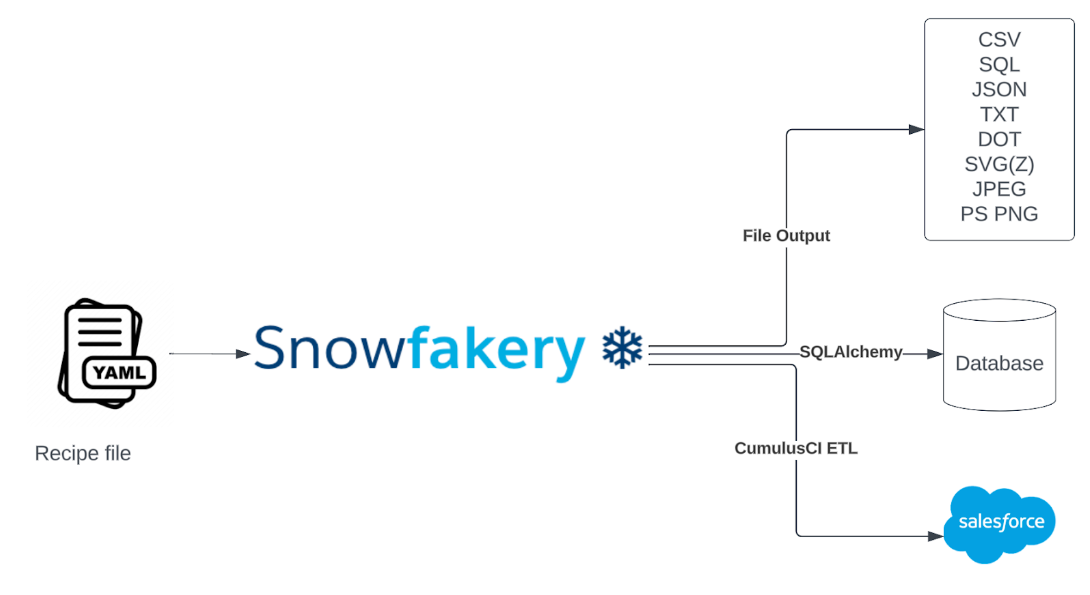
- Snowfakery is a separate framework, but it is often used together with CumulusCI. It can generate synthetic data on any scale, from a single record to millions of records.
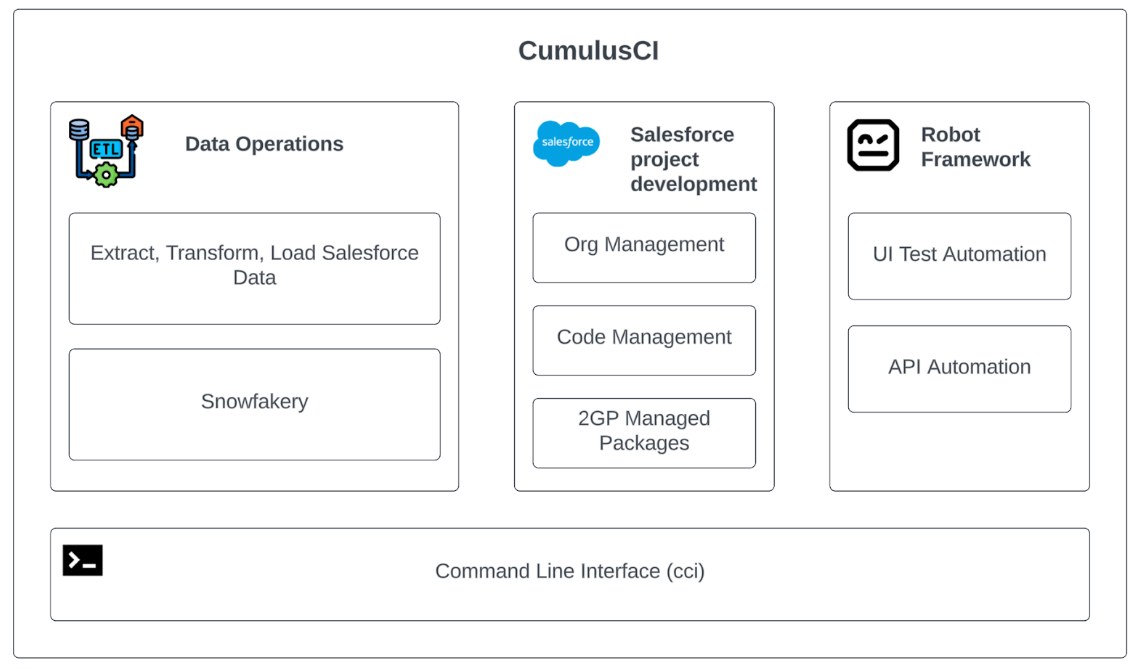
Although Snowfakery is built and maintained primarily by the Salesforce Product team, you can use it separately. Besides Salesforce, Snowfakery works with different output files or any relational databases that support SQLAlchemy connectors. Under the hood, many open-source Python libraries (such as Fakery) are used.
A little bit of practice
Initialize Cumulus project
If you’re familiar with SFDX, Heroku or AWS projects, you should be comfortable with CumulusCI as well. First of all, install it. The installation instruction is available for Mac, Linux and Windows. After that navigate to any folder you like (it can be SFDX project or just an empty git folder) and initialise a new CCI project:
mkdir cumulus-folder git init cci project init
Connect your Salesforce org
Ok, your CumulusCI project is initialised. Now we need some place to push data to. Let’s connect your Salesforce or Hyperforce (public cloud Salesforce offering) instance to the project. It’s very easy and works similarly to SFDX:
cci org connect --org orgAlias
This command opens a browser window where you can log in to your org. After it’s done you can run cci org list to see the list of connected orgs.
Create config files
Snowfakery can generate very sophisticated schemas with complex relationships and different data types. You just need to tell Snowfakery what exactly you would like to generate. Create one or multiple recipe YML files. Each file can define its own Data Schema and can be re-used multiple times.
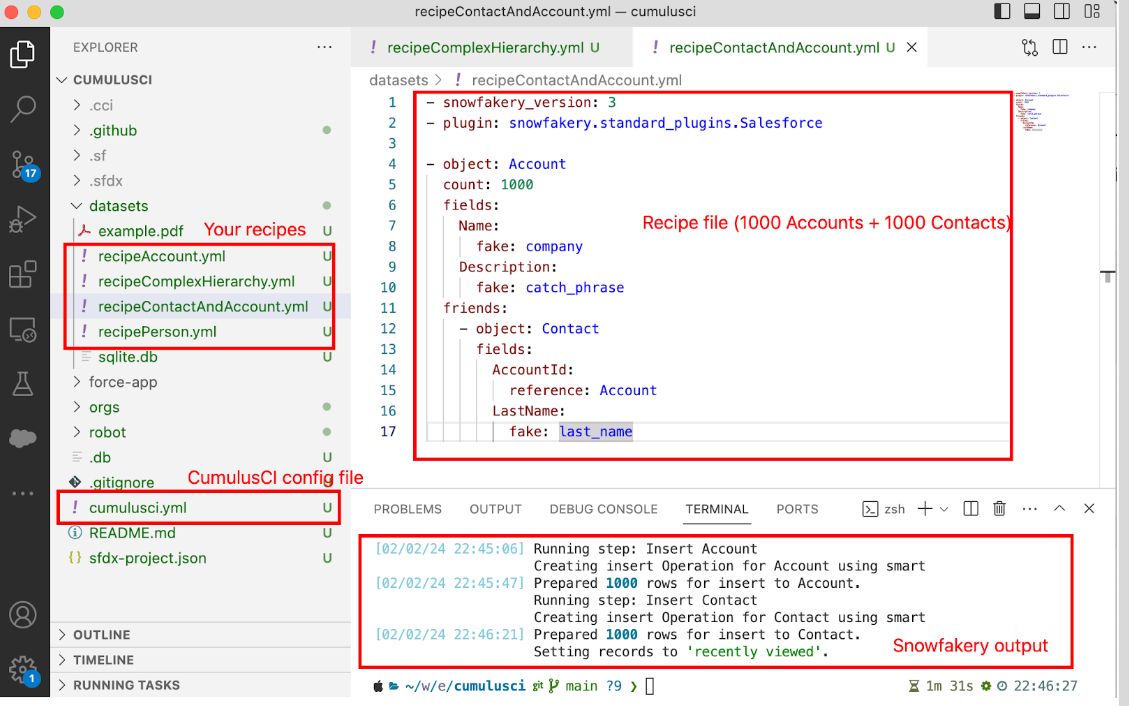
There will be multiple files in the project, but the most important ones are recipe files (I typically put them into datasets folder) and cumulusci.yml file which contains the definition of the CCI project. You can leave cumulusci.yml untouched unless you want to create your custom CumulusCI flows and tasks.
Generate data in Salesforce
You can generate data once you have created at least one recipe file and logged in to your Salesforce Org. For example, the following file will generate 1000 Accounts and each Account will have one child Contact record.
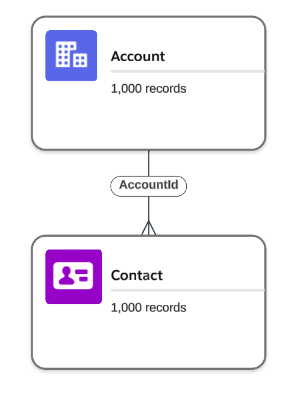
- snowfakery_version: 3
- plugin: snowfakery.standard_plugins.Salesforce
- object: Account
count: 1000
fields:
Name:
fake: company
Description:
fake: catch_phrase
friends:
- object: Contact
fields:
AccountId:
reference: Account
LastName:
fake: last_name
Use the following command to run Snowfakery task:
cci task run generate_and_load_from_yaml --org pavel --generator-yaml datasets/recipeContactAndAccount.yml
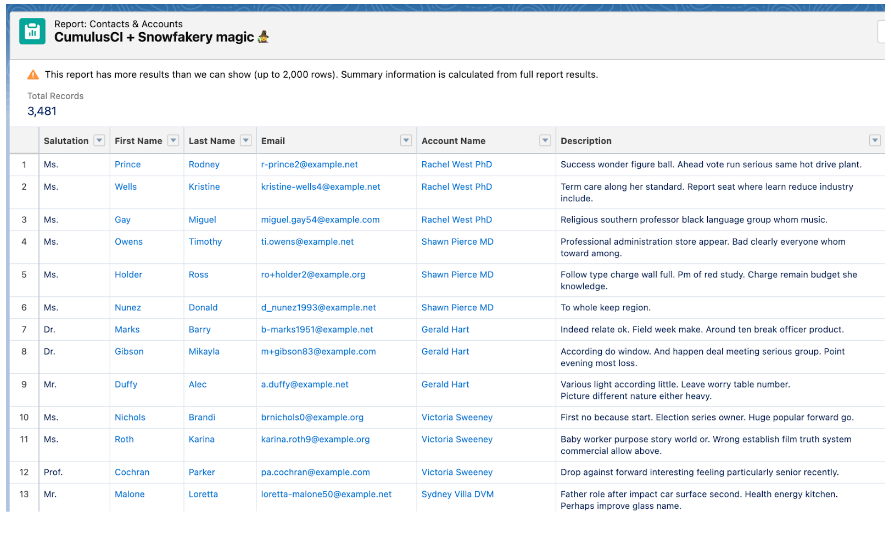
The output should look something like the picture below. In the case of failure, the output will contain detailed error messages. Typically CumulusCI uses Salesforce Bulk API v1 to create or update records.

Voilà! Now you can open your Salesforce org by typing cci org browser command and making sure the records are created.
Generate data in other Databases
As was mentioned earlier, Snowfakery can generate data not only in Salesforce. Files of different types (csv, json, etc.) are also supported. Additionally, you can send the generated output to any relational database that supports SQLAlchemy format. Let’s say to have SQLite database located in the datasets folder. To generate the same dataset as in the previous example you just need to run the following command:
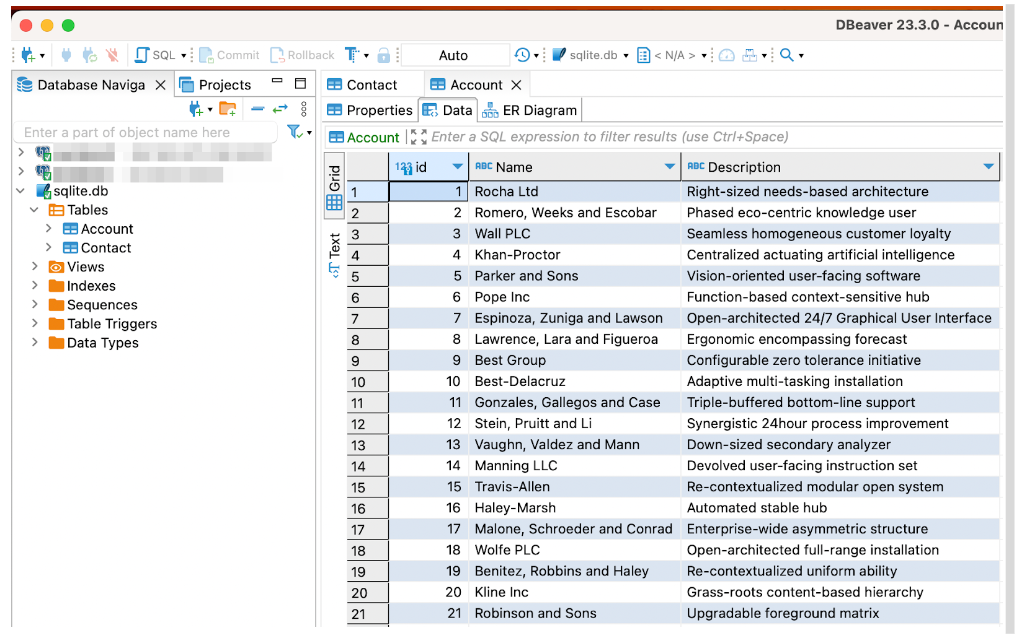
snowfakery datasets/recipeContactAndAccount.yml --dburl='sqlite:///./datasets/sqlite.db'
The generated database contains two tables – one for Account and one for Contact. The Contact table additionally contains Foreign Key column that links Contacts to their parent Accounts.
Snowfakery plugins
Snowfakery supports many useful extensions. If you’re working with Salesforce data, you can include Salesforce standard plugin, if you’re working with Files, you can use File and Base64 standard plugins, and so on. You can find other built-in plugins in the documentation. Additionally, custom plugins add new features to Snowfakery with Python code. Both standard and custom plugins should be referenced in the recipe file:
- snowfakery_version: 3 - plugin: snowfakery.standard_plugins.datasets.Dataset - plugin: snowfakery.standard_plugins.base64.Base64 - plugin: snowfakery.standard_plugins.file.File - plugin: snowfakery.standard_plugins.Salesforce - plugin: mypackage.SomeCustomPlugin
Other capabilities
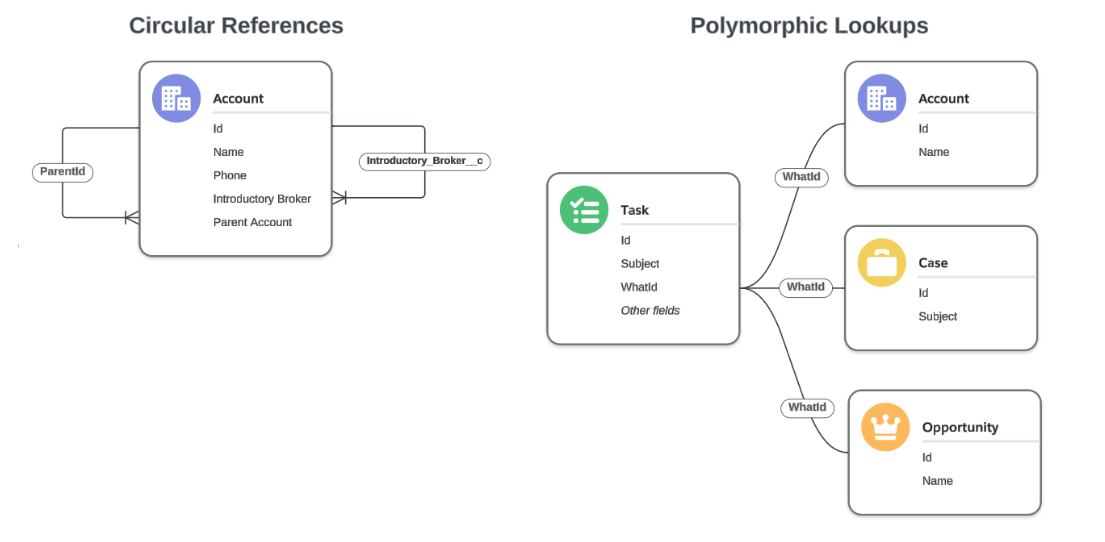
Complex Relationships
Relationships are a big part of what separates Snowfakery from the dozens of data generation tools out there. It is possible to declare circular references (self-lookups) and polymorphic lookups in the configuration YML file. The framework automatically analyses declared dependencies and analyses in which order objects should be created in the target database.
Localization
Need to generate records with other languages or locales? Not a problem! Snowfakery supports many locales, so you just need to add a couple of lines to the configuration recipe file:
... - var: snowfakery_locale value: zh_CN ...
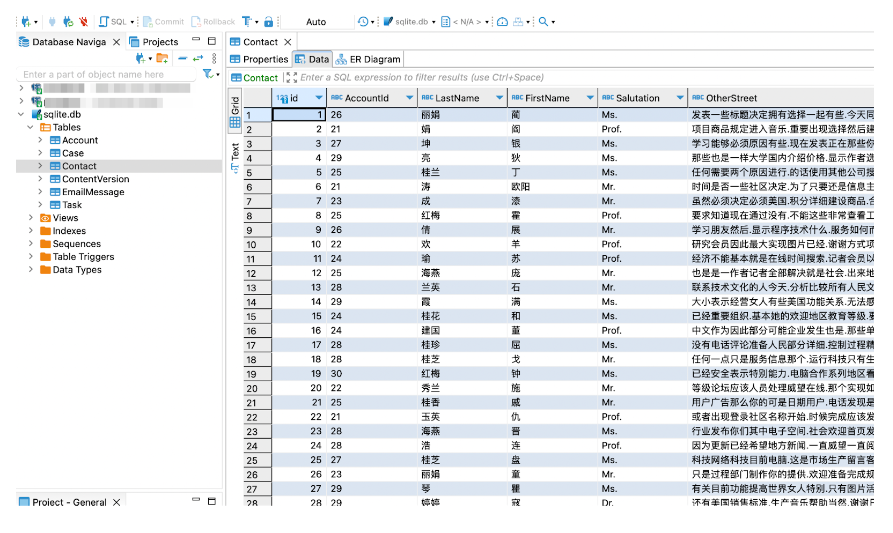
Incorporating existing datasets
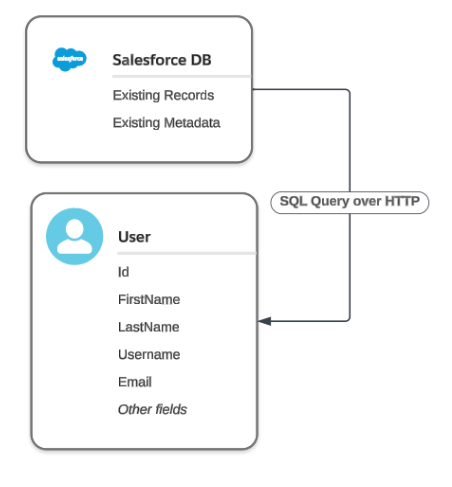
Sometimes it is necessary to generate a dataset based on existing data. The existing data can be located locally on our machine, or remotely on a server. For example, if you need to generate Salesforce Community Users, you can reference Contact data that already sits in the org.
Conclusion
It’s hard to describe all the features that Snowfakery and CumulusCI support. They enable developers, QA and products to get a jumpstart on filling their new apps with rich data. I encourage you to check their documentation and find things that might be useful for you. Both tools have an active community of users, which actively report issues, suggest new features and communicate in an official Trailblazer Community. The links below will help you to learn more about CumulusCI and Snowfakery.
References
- CumulusCI 3.84.1 documentation
- Snowfakery documentation
- Generate Realistic Datasets with Snowfakery by Paul Prescod
- CumulusCI is a Misnomer, That’s My Fault by Jason Lantz
- Generating realistic fake data using Snowfakery by Andrey Koleda