
As Ebury fully embraces new architectures supporting our business growth, we’ve selected Kafka to be a backbone of system integrations. Here you will find 4 cases where it has been implemented successfully:
1 – Data Migration (a.k.a. Database Consolidation Service)
Ebury has one system that has been leased to a client with all the same capabilities in the past. As time went by, this client was acquired by Ebury, and now it’s part of the same organisation. That created a problem: Now we have one system running over 2 different infrastructures, which means 2 instances of its database. In order to consolidate this system into a single one, we need to consolidate its data.
Since it’s a complex system, which grew apart in 2 different places, there are some reasons why we cannot just use a simple database-replication from point A to point B, such as primary key conflicts.
Let’s say you have a client, with primary key equals 42 in the source DB. Since both DBs grew apart from each other, the client with the same primary key (42) in the destination DB will be a different client.
Kafka to the rescue. Kafka doesn’t mean just the main component, but all of Kafka’s ecosystem, including Kafka Connect and specific CDC connectors.
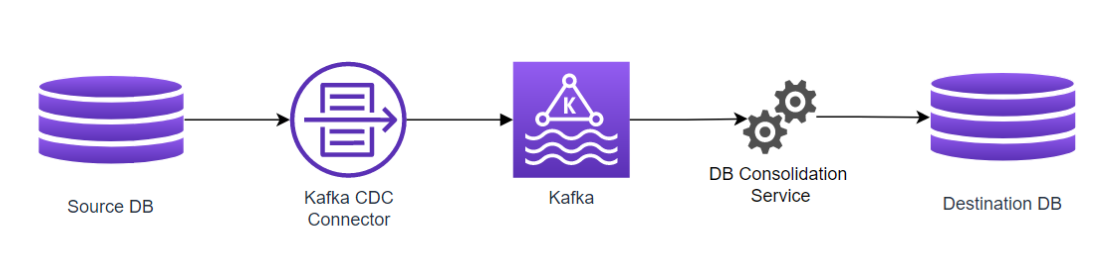
The CDC Connector reads directly the database logs as they’re written, generating events for each insert/update/delete on it, allowing us to capture all the changes in the DB without impacting it.
Each table has its own topic inside Kafka, which means that the DB Consolidation Service can then read the appropriate topics, and consolidate the information on the destination database, generating the primary key translations as needed.
2 – Account Details Service (a.k.a. Microservice Pattern)
Allowing our clients to create their own accounts is a key process inside our business.
But the account creation process has several caveats. Each account must go through a validation process, and feed a number of different applications. That means each application must manage the accounts in the same way, and must be synchronised regarding the account status, such as “enabled” or “disabled”.
In order to solve this problem, we created a microservice which will manage all the client requests and handle the business validation of the accounts, and for each status change, this service will generate a Domain Event [1] that will feed the legacy applications.
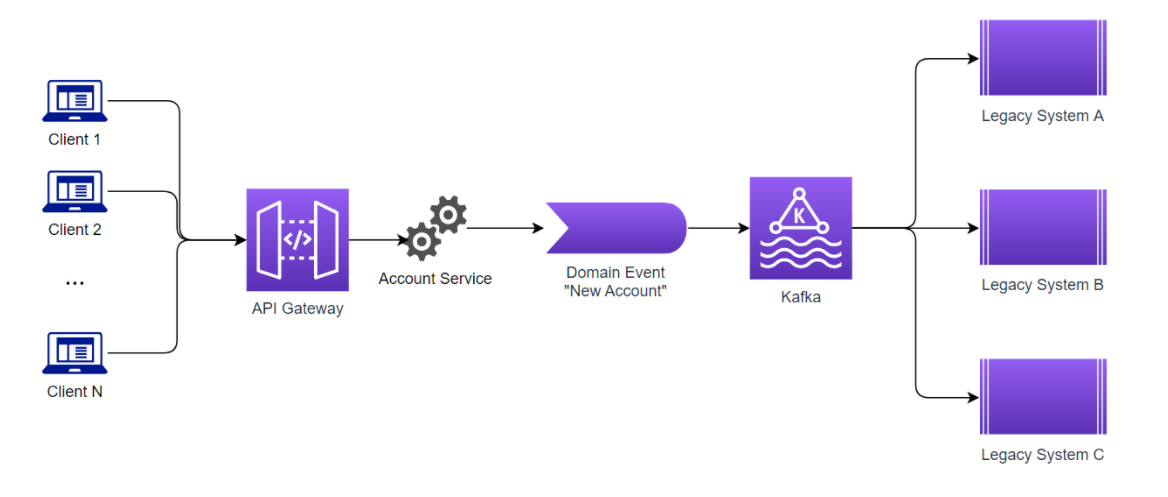
These events range from “New Account Created”, to “Account Deactivated” and all the in-betweens necessary to manage the accounts, in a single place. The legacy applications can then listen to these events, and enable/disable the accounts as needed.
Also, changes in the accounts (such as an email update), will also generate domain events, and keep the whole system updated.
Since the process is asynchronous, we can trigger additional Sagas [1] for the accounts as they are enabled and/or disabled, allowing a higher level of automation
3 – Beneficiary Query Service – CQRS Pattern
Command Query Responsibility Segregation is a pattern where you separate your data-changing statements (commands) from your queries [2]. Although not necessary, a common pattern is to separate your command database from your queries databases, in order to have different workloads on different machines, and synchronise data between these two. This separation is effective if the synchronisation between the two databases is done in (almost) real-time.
We apply this concept in a legacy application, where all the commands are stored (insert a new client, change address of this other client, change telephone of this third one, etc), and for each change, a new Domain Event is generated, updating another database used specifically for queries.
Kafka acts as the data bus allowing synchronous command requests to be unbound from eventually consistent data in our query services.
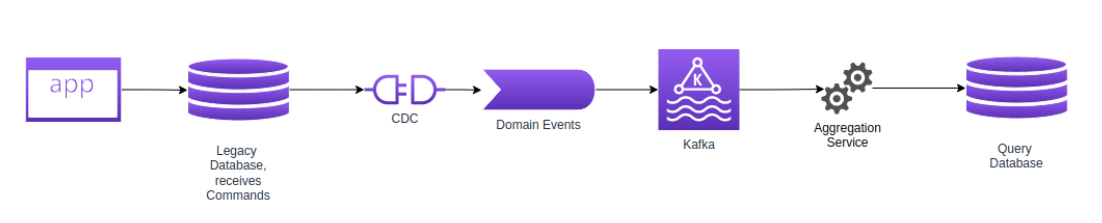
It may not sound that impressive at first, but what if I told you that this simple concept reduced the workload on this legacy application, while also allowing an output of queries 50x faster on the new service and opens up options such as geo distribution of query services to put our systems and data closer to our clients worldwide?
Also, using CQRS opens up a door to use more advanced architectures such as Event Sourcing [3].
4 – Data lake
Another use we have for Kafka is to serve as our main backbone for feeding a data lake that provides an environment for big query analysis of our data.
As our applications grow, there is no need to add new and convoluted integrations on these systems, as the Kafka connectors used already provide a great level of adaptability to data changes, while also providing almost real time data feed to our analysts
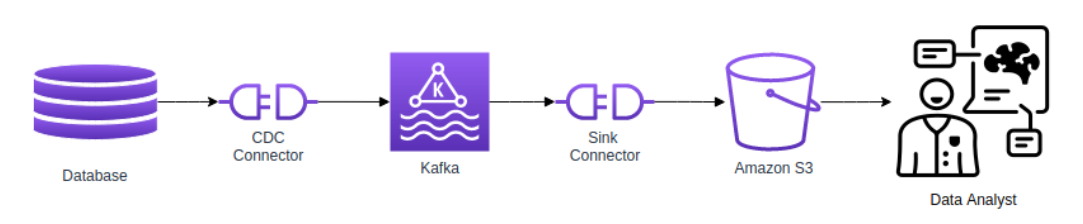
By leveraging the Kafka ecosystem here for data delivery, we can focus our resources on the important part of the problem, which is data analysis.
No silver bullet
There is no single piece of technology that will solve all problems. Having Kafka to enable systems integration, for CQRS or Event Sourcing is great, but also brings its own challenges, as the CAP Theorem still applies.
Also, asynchronous communication is always harder to manage than synchronous communication, which means that we still have CRUD applications where it’s rational to have a simpler approach.
That being said, it’s a fact that Kafka high-performance, high-availability and high-scalability enabled faster development cycles and better usage of our resources.
References:
[1] You can check more details on Domain Events and Sagas on the links below:
- https://microservices.io/patterns/data/domain-event.html
- https://martinfowler.com/eaaDev/DomainEvent.html
- https://microservices.io/patterns/data/saga.html
- https://docs.aws.amazon.com/prescriptive-guidance/latest/modernization-data-persistence/saga-pattern.html
- https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/saga/saga
[2] CQRS patterns:
- https://martinfowler.com/bliki/CQRS.html
- https://docs.microsoft.com/en-us/azure/architecture/patterns/cqrs
- https://docs.aws.amazon.com/prescriptive-guidance/latest/modernization-data-persistence/cqrs-pattern.html
[3] Event Sourcing
- https://docs.aws.amazon.com/prescriptive-guidance/latest/modernization-data-persistence/service-per-team.html
- https://martinfowler.com/eaaDev/EventSourcing.html
- https://docs.microsoft.com/en-us/azure/architecture/patterns/event-sourcing