This post was first published in aivarsk.com
My journey to understand the performance and concurrency of FastAPI services lead me to the Python json.dumps function producing JSON string out of object tree. And I ended up making it a bit faster.
_PyAccu vs _PyUnicodeWriter
How do you create the JSON string out of string representation of all objects in the tree? json.dumps C implementation used _PyAccu for that.
_PyAccu maintains two lists of strings: small and large. All strings are added to the small list first. Once it contains 100,000 (!!!) elements, all of them are joined together and the result is added to the large list. Python pseudo-code for that would be like this:
large = []
small = []
while True:
small.append(some_string)
if len(small) == 100000:
large.append(''.join(small))
del small[:]
large.append(''.join(small))
return large
I did not like this algorithm from the first sight and believed that you can do better and faster than accumulating a lot of small objects only to discard them all at once later.
The way memory allocation works in most software makes memory usage go up easily but never go down. Even when memory is released it’s still reserved for the process. There are some conditions and some allocators that can release memory back to the operating system if the “tail” of memory is no longer needed. But those are exceptions and not the norm. Also when many small objects are released some allocators try to join the freed space into a larger area and that takes time.
From the algorithmic point of view once we have to join all 100,000 strings the code goes through it twice: once to calculate the total size and second time to copy the content to the resulting string. This will trash the CPU cache going after each object but that might not be a significant hit for interpreted Python code.
After going through the source code and looking at different APIs and implementation details I could use for a better accumulator I found out there is an alternative solution already: _PyUnicodeWriter. I like the approach _PyUnicodeWriter takes and that would be my go-to solution. The algorithm is very simple: it just appends the new string to the resulting string.
result = ''
while True:
result += some_string
return result
The main trick here is to over-allocate the memory needed for the resulting string. Without that, a new result string would be created each time and the content of the old result and some_string would be copied over. With over-allocation, there is some extra space in the result string and reallocation and copying of content do not happen every time. I would simply double the size every time but CPython increases that by 25% on Linux and 50% on Windows.
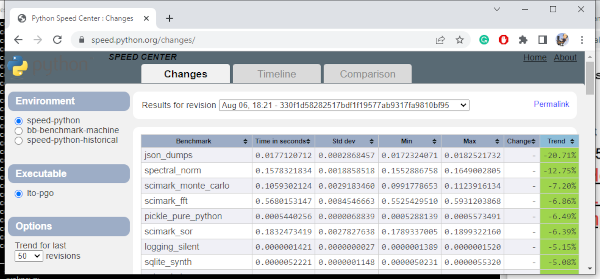
I made a change to replace _PyAccu with _PyUnicodeWriter and it resulted in a small performance boost in pyperformance benchmark as well. Turned out that _PyAccu was used only in two places in the whole code base so I replaced _PyAccu everywhere and deleted it completely. Not only json.dumps became faster, CPython got smaller by at least 100 lines of code.
Fast-path for the default case
The C implementation of json.dumps takes a couple of parameters that affect the output. One of those is sort_keys=False to request sorting of dictionary keys. The implementation of the feature would be something like this in Python pseudo-code:
items = list(pydict.items())
if sort_keys:
items.sort()
for key, value in items:
...
If you keep in mind that sort_keys is False by default and look at the code carefully you will notice the creation of a list of tuples containing key and value pairs. That seems wasteful when sorting is not performed. So I added a separate code path to iterate over dictionary items directly without creating copies. Which was easy and the main challenge was to reuse the body of the loop between both code paths.
if sort_keys:
items = list(pydict.items())
items.sort()
for key, value in items:
...
else:
for key, value in pydict.items():
...