
Unless you’ve been in a cave for the last year, you may have noticed how “Serverless” is the new sticky word in the dev community and it’s like we’ve not had time to get used to the “Microservices” buzz. But don’t go crazy just yet, it’s not the time throw away your “still hot” blueprint of your architecture because a new trending topic has arrived. We decided to keep it cool and just experiment a little bit.
This blog describes how we used AWS Lambda and overcame some of its current limitations to solve a typical data processing pipeline problem.
Not long ago, we had the chance to revamp one of our ETL processes, which injects information from our main back office application into Birst, our key Business Intelligence tool. We had two daily processes, one from the back office system generating information to be uploaded, and a separate Birst process to ingest this data, but these process were completely disconnected and so timing issues would cause problems and potentially result in failure. It’s here where we decided to experiment with two things, Birst’s API and Amazon Lambda, which in Lambda’s case is an exceptional start point if you want to play a little bit with this new “Serverless” technology.
Thanks to the integration that Lambda has with many other Amazon services, it allows us to launch functions based on service events, and it’s precisely an S3 event from where we wanted to start. On the whiteboard, everything was pretty clear: once we generate our report from the back office and upload it to S3, a lambda function will be triggered that will use the Birst API to upload the file and run the required ETL jobs, sending some emails notifications once everything is done. We then stumbled upon a little issue: lambda only allows 5 minutes of total execution for each lambda invoked, and the Birst ETL process could take up to 40 minutes.
Our initial thought was, “well, we could create one lambda function hooked up with the S3 event to upload the file, and to have another one scheduled to be executed every 5 minutes which checks the status of the process“, but this had other problems as well. We use a Birst token provided by the API to check on job statuses and now for this to work we would need to persistence the token on the first lambda function, and to retrieve it in the second one. But what happens if two reports are generated at the same time? Should we be checking a list of tokens every 5 minutes? At this point it’s starting to get complicated, we have to store the token of the Birst process using… DynamoDB maybe? We are trying to use Lambda because it’s cheap and comfy but it’s gonna be a riddle just to deploy it and to maintain with a database as well, maybe it’s easier to come back to a good old crontab.
But, thinking a little bit more creatively on this, we decided to try to hijack Lambda by making the function recursive. “What if we make a lambda function that calls itself once it is running out of time?” As it happens, boto3, the python library that controls AWS client, has natively included this into the Lambda environment, very handy!
Let’s see an example of this so you can replicate it for yourself. First of all, we need to create a new lambda function using the wizard. Skip the templates and, in the next step, the event which we will be triggering it is irrelevant so in my example I will select S3 Put:
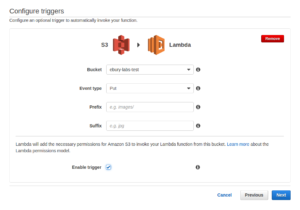
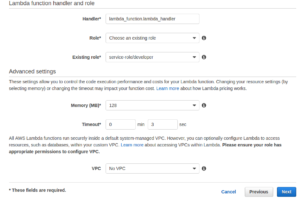
In the second step, name your lambda function, select the interpreter (for this example we will use Python 2.7.3), choose the appropriate level of permissions that you want to assign to the function and the amount of resources that it will need (with the default values is ok). For this example we will change the timeout to 10 secs. Finish the rest of the steps in the wizard and then we are ready to start coding.
In the lambda editor, you can find a tab named code, which takes you to an inline editor to modify your function. Remove everything and paste this code:
import json
import boto3
import logging
AWS_ACCESS_KEY_ID = "YOURAWSACCESSKEYIDHERE"
AWS_SECRET_ACCESS_KEY = "YOURSECRETACCESSKEYHERE"
MAX_RETRIES = 4
TIMEOUT_REMAINING = 5000
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
"""
This is the main function that Amazon Lambda will call in order to
start the execution
"""
# execute loop while time remaining is higher that timeout period
while context.get_remaining_time_in_millis() > TIMEOUT_REMAINING:
# do whatever retries function you want
# (make sure the execution time here is lower than the TIMEOUT_REMAINING time)
continue
else:
# relaunch lambda function if retries left
retries_left = update_num_retries(event)
if retries_left > 0:
relaunch_lambda(event, context)
else:
return False
def update_num_retries(event):
"""
Updates the number of iterations left that the lambda function.
"""
if not event.get("NUM_RETRIES"):
event["NUM_RETRIES"] = MAX_RETRIES
elif event.get("NUM_RETRIES") > 0:
event["NUM_RETRIES"] = event.get("NUM_RETRIES")-1
logger.info("Number of retries left: %d" % event["NUM_RETRIES"])
return event.get("NUM_RETRIES")
def relaunch_lambda(event, context):
"""
Creates a new AWS client and execute the same lambda function
asynchronously
"""
session = boto3.session.Session(aws_access_key_id=AWS_ACCESS_KEY_ID, aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
lambda_cli = session.client("lambda")
lambda_cli.invoke_async(FunctionName=context.function_name, InvokeArgs=json.dumps(event))
If you look at the code, we create a main lambda function lambda_handle, which will be the one invoked by Amazon to run the process. Here, we have declared a loop, that could, for example, call an external API for an status until you receive what you need. If the execution time of the lambda surpass a threshold, it will quit the loop, update the number of retries and launch the function again if it didn’t run out of chances. Notice that you need to change the AWS credentials in order to make it run in your environment.
Save and run. After 5 seconds, the lambda will finish the test, but just the first iteration, the other 4 retries will be executing in the background. Thanks to the integration with Amazon CloudWatch, we are able to see log entries for the whole execution, just by clicking on the logs link.

Of course, Amazon Lambda is not really designed to work this way, but sometimes is good to push the limits and find workarounds to the service. Lambda is still at an early stage and many features will surely come in the next months. Some of the functionality we would like to see are:
- Integration with repositories like git
- Extension (or just the removal) of the execution time
- Testing environment integration, maybe with external IDEs (the inline editor is not the best debugger, to be honest)
- The possibility to launch delayed functions
- Python 3 compatibility
- Environment variables
I hope you like it! If you have any suggestions please leave them below in the comments section 😀
PS. Special thanks go to my colleague Abraham Gonzalez, who suffered my stubbornness during this process.