
When we talk about Unit Tests we generally mean tests for individual units of source code as created as an outcome of Test Driven Development. But how can we apply this when we’re developing against areas of our code base that don’t have unit tests to start with, that is essentially Legacy code?
This post describes how we approached this problem in three phases.
The ideal setup
The target for every company is to create a set of test coverage in the shape of the pyramid below.
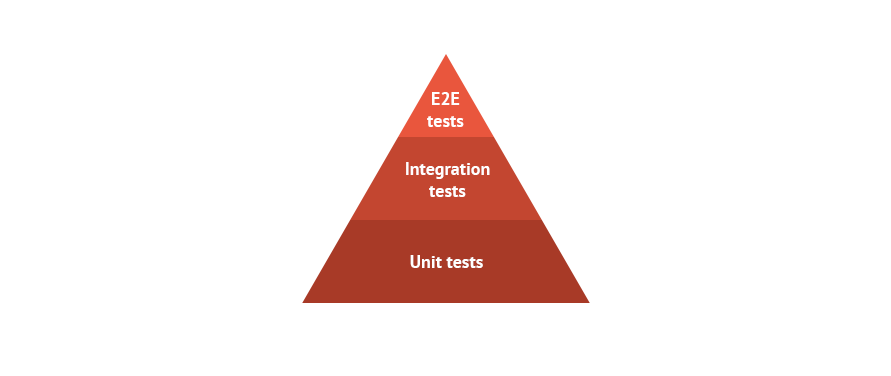
- E2E or end to end, are automated GUI tests. We use a combination of Behave + Selenium + Python.
- Integration tests, for which we use the pytests library.
- Unit tests, for which we also use the pytests library (these evolve from TDD philosophy)
Generating this type of coverage for greenfield development is fairly well understood, but what happens when parts of the codebase we are working with are legacy? (At Ebury, we think of legacy code as code without unit tests).
Let’s explore how we’re approaching this shape on the legacy part of our codebase, step-by-step:
First phase
We first made a decision not to throw away everything that was legacy. Everything was working well but the cost to make changes in those legacy areas was increasing and so our ability to change stuff was getting slower.
Unfortunately you can’t just jump in and start adding unit tests as the structure of the code has not been built to be tested. Its too risky at this stage to just change the code to add unit tests, as you don’t know what you might be breaking.
We didn’t have an E2E framework in place. So initially we worked to increase the coverage through integration tests. Our pyramid was inverted.
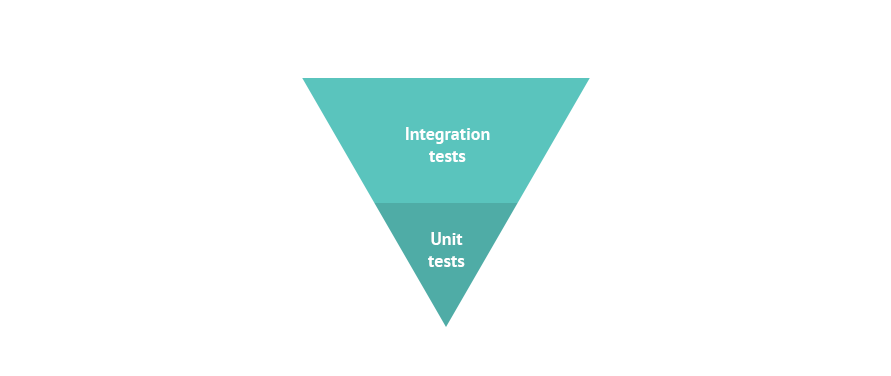
Second phase
Next we included E2E Tests.
Again a UI needs to be designed and have the hooks in place to be tested. While perhaps not an approach we would recommend for all projects, we had an opportunity to kill two birds with one stone: To meet various requirements to update the look and feel of our application and add E2E coverage as we went.
It’s worth noting that E2E tests can take along time to execute. We started running them overnight but, as the number increased, we had to do work to parallelise the running of these E2E and indeed other tests so our CI process itself did not become a bottleneck.
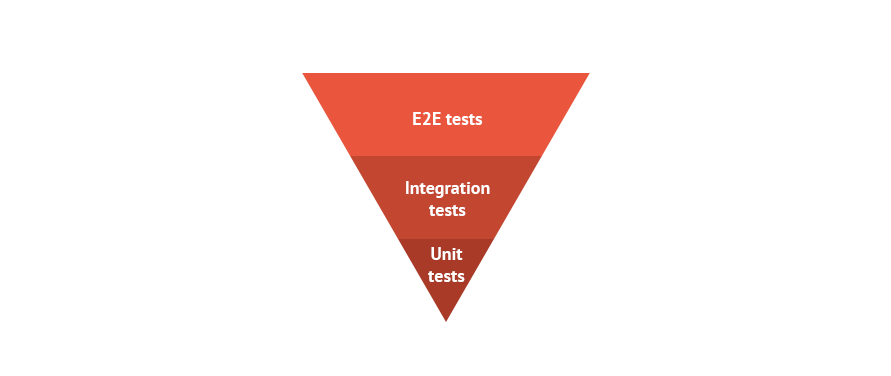
Third phase
With good top end coverage in place, we were able to begin fixing our pyramid, not as a specific project but just as changes were needed. When touching the legacy code we began to add unit tests, remove or “mock” out dependencies in the parts of the code needing to be changed, ensuring that tests were failing for the right reasons and then adding what’s needed to get the new tests to pass.
Michael C. Feathers ‘Working Effectively with Legacy Code’ is a very useful guideline for the approach we have taken here.
What have we got now?
So currently our “pyramid” for the original code feels a bit more like a trapeze:
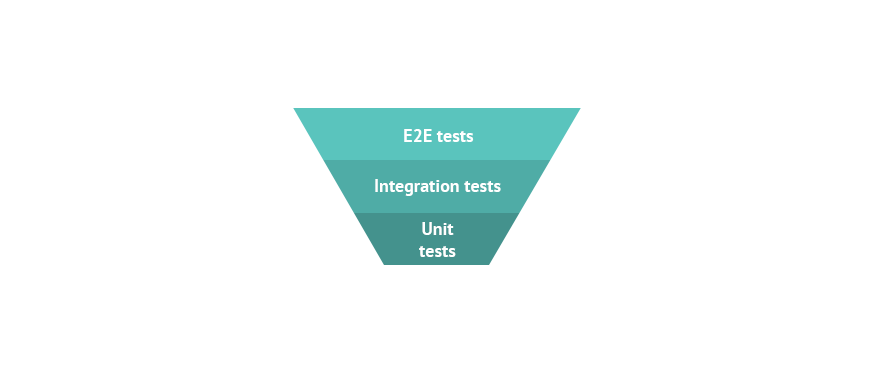
Over time we have seen our unit test coverage increase and most importantly a significant drop in defects getting to production. We’re pretty happy with our E2E Test coverage and are continuously increasing the Integration and Unit Tests coverage.
Importantly we have considerably reduced the test execution time, down from many hours to around thirty minutes. The key changes we have made to achieve this are:
- Removing or mocking out the most significant external dependencies
- Using multiple cloud servers to execute the process through Docker containers
- Avoiding manual execution using Bitbucket + Jenkins + Docker integration
- Parallelisation and prioritisation of Jenkins jobs
This is our current set up for executing tests:
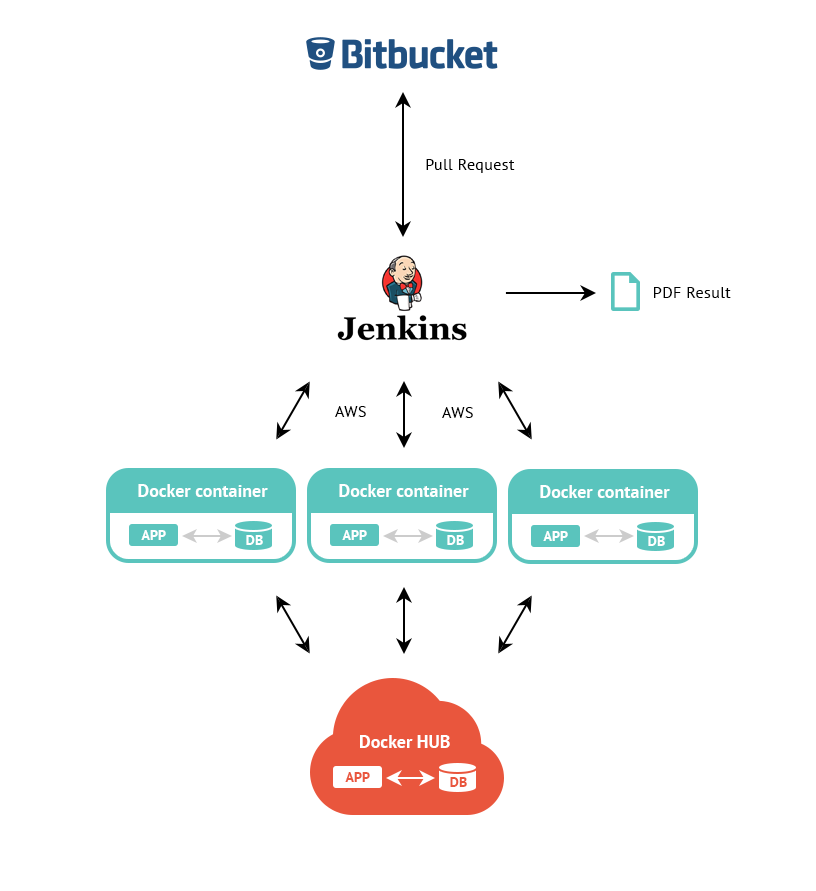
Whats next?
We’ll continue to invest in the shape of our pyramid and we have plans to speed everything up further with:
- Database execution in memory
- Continuing to remove or design-out more dependencies
I hope you find this story helpful and can see how it may be applied to your own project.
In the next post, we’ll talk about how we included coverage analysis in this process.
Thanks!